KeyWords: string-matching, pattern-matching, indexing, inverted text, finite-automata, suffix-trees, suffix-automata,suffix-tries, factor-automata, music identification, Directed Acycle Word Graph (DAWG).
Let me name some common problems on string.
finding Least Common String of strings, Sub String search, Palindromes, Angarams,
Dictionary search, Commonly occuring string (Atom String), unique significant substring/pattern,
least common prefix, least common suffix, whats not in the list.
The key point for solving all of these problems is , maintain all data about a string.
All data about a string means {All prefix substrings,All suffix substrings, All sub-strings} .
What matters here ??
You can solve string related problems using, either Brute Force method or using some Data Structure which will allow you to store data about string, considering your time/space complexities.
the way your data-structure stores data about the string? -Time and space taken for processing of the string.
the way your data-structure retrieves data about the string?- Query response time /time taken to retrieve the data.
If you are going to use data-structures, here are the few structure that you'll obvisouly look out for.
Data about strings can be comprised in either a Suffix-Tree/Trie or Suffx-Array or Finite-Automata or Factor-Oracle.
So many people did a vast research on the area of string processing.If this area interests you as well, then you should go throught the sources mentione at the end of this post.
Since, space-time are driving factors in dealing with large data, i prefer to construct a suffx automata(DAWG), for the problems on strings.
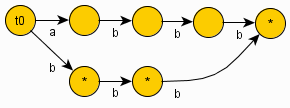
Examples of DAWGs:
For String ""
For String "a"
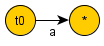
For String "aa"

For String "ab"
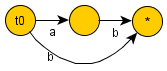
For String "aba"
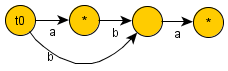
For String "abb"
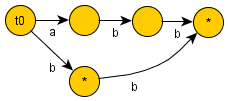
For String "abbb"
Explanation(Example String: "GCAGAGAG"):
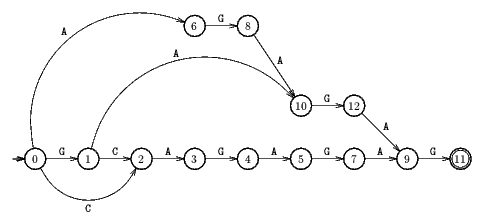
State-3 is cloned as State-6 while inserting 2nd 'A', after state-4, to allow DAG Flow for the suffix string AGAGAG,AGXXXX
State-4 is cloned as State-8 while inserting 2nd 'G', after state-6, to allow DAG Flow for the suffix string GAGAG,GAXXX.
...Just do some work around on this string further, you will understand.
Constructing Suffix-Automata in O(N)-Time / O(N logK) space(Forward DAWG Matching algorithm):
Forward DAWG Matching algorithm, which is smallest suffix automation with Deterministic Finite Automaton.How to Construct: 1. Define the statetypedef struct state{ int length; //Length of the DAWG till this state state* prev; //Link to previous transition state in the DAWG state* next[ALPHA_MAX]; //Links to next transition state in the DAWG } state;2. Automata is constructed with set of states and transition from state-to-state. So define your Automata which comprises of the states, variables to track states and methods that enables to do state transitions.typedef struct SAM{ /*FSM Variables*/ state pool[MAX]; //You need a pool of states, from where you can pick a raw state to include in the DAWG. int count; //You need to track number of states present in the DAWG. state* head,last; //You need to track your head of the DAWG and last State of the DAWG. /*FSM Methods*/ void SAM_init(); //Initialize your Finite state Machine. voidSAM_extend(int input); //Based on the input extend states in your FSM(Finite State Machine) } SAM;3. Initialization of FSM.void SAM::SAM_init(){ memset(pool,0,sizeof(pool)); count=0; head=last=&pool[count++]; }4. Extending the FSM.void SAM::SAM_extend(int input){ state* new_state = &pool[count++]; new_state->length = 1 + last->length; state* p = last; for( ; p && !p->next[input]; p->next[input]=new_state,p=p->prev); if(!p){ new_state->prev = head; }else{ state* q = p->next[input]; if(p->length +1 == q->length){ new_state->prev = q; }else{ state* clone = &pool[total++]; *clone = *q; clone->length = p->length +1; for(;p && p->next[input]==q;p->next[input]=clone,p=p->prev); new_state->prev = q->prev = clone; } } last = new_state; }5. You can include other methods, If required (like below method, which i used it for the traversal of the DAWG.)void SAM::SAM_traverse(state** p,int& len,int input){ while(*p!=head && !(*p)->next[input]){ *p = (*p)->link; len = (*p)->length; } if((*p)->next[input]){ *p = (*p)->next[input]; len++; } }Sources: http://www.cs.nyu.edu/~mohri/pub/nfac.pdf http://cbse.soe.ucsc.edu/sites/default/files/smallest_automaton1985.pdf http://www-igm.univ-mlv.fr/~lecroq/string/fdm.html#SECTION00220 http://e-maxx.ru/algo/suffix_automata http://www-igm.univ-mlv.fr/~lecroq/string/node1.html Practise problems: http://www.spoj.com/problems/LCS/ http://www.spoj.com/problems/LCS2/
 Case-2::No Overlapping
result would be max of
{
(x1,x2-1).bestRightSum + (x2,y2).bestLeftSum,
(x1,y1).bestRightSum + (y1+1,y2).bestLeftSum,
(x2,y1).bestSum
}
Case-2::No Overlapping
result would be max of
{
(x1,x2-1).bestRightSum + (x2,y2).bestLeftSum,
(x1,y1).bestRightSum + (y1+1,y2).bestLeftSum,
(x2,y1).bestSum
}






