// =====================================================================================
// Description:
// Author: BrOkEN@!
// =====================================================================================
#include<fstream>
#include<iostream>
#include<sstream>
#include<bitset>
#include<deque>
#include<list>
#include<map>
#include<queue>
#include<set>
#include<stack>
#include<vector>
#include<algorithm>
#include<iterator>
#include<string>
#include<cassert>
#include<cctype>
#include<climits>
#include<cmath>
#include<cstddef>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<ctime>
using namespace std;
template< class T > inline T _maxOfThree(T a,T b,T c) {return max(max(a,b),c);}
template< class T > inline T _abs(T n) { return (n < 0 ? -n : n); }
template< class T > T _square(T x) { return x * x; }
template< class T > T gcd(T a, T b) { return (b != 0 ? gcd<T>(b, a%b) : a); }
template< class T > T lcm(T a, T b) { return (a / gcd<T>(a, b) * b); }
template< class T > bool in_range(T x, T i, T y) { return x<=i && i<=y; }
#define FOR(i,a,b) for(typeof((a)) i=(a); i <= (b) ; ++i)
#define REV_FOR(i,a,b) for(typeof((a)) i=(a); i >= (b) ; --i)
#define FOREACH(it,x) for(typeof((x).begin()) it=(x).begin(); it != (x).end() ; ++it)
#define REV_FOREACH(it,x) for(typeof((x).rbegin()) it=(x).rbegin(); it != (x).rend() ; ++it)
#define SET(p, v) memset(p, v, sizeof(p))
#define CPY(p, v) memcpy(p, v, sizeof(p))
#define CLR(p) SET(p,0)
#define READ(f) freopen(f, "r", stdin)
#define WRITE(f) freopen(f, "w", stdout)
#define ARRAY_SIZE(array) (sizeof(array) / sizeof((array)[0]))
#define __int64 long long
typedef pair<int,int> PI;
typedef vector<PI> VI;
const int ALPHA_MAX = 26;
const int MAX = 201000;
typedef struct state{
int length;
state* link;
state* next[ALPHA_MAX];
int lcs,nlcs;
} state;
int total=0;
state pool[MAX<<1];
state* tpool[MAX<<1];
int counts[MAX];
state* head;
state* last;
void sam_init(){
head=last=&pool[total++];
}
void sam_track(int length){
for(int i=0;i<total;i++) counts[pool[i].length]++;
for(int i=1;i<=length;i++) counts[i]+=counts[i-1];
for(int i=0;i<total;i++) { tpool[--counts[pool[i].length]]=&pool[i]; }
}
void sam_updateBests(){
state* p=NULL;
for(int i=total-1;i>=0;i--) {
p=tpool[i];
if(p->lcs<p->nlcs) p->nlcs = p->lcs;
if(p->link && p->link->lcs<p->lcs) p->link->lcs = p->lcs;
p->lcs =0;
}
}
int sam_best(){
int ans=0;
for(int i=0;i<total;i++) if(pool[i].nlcs>ans) ans=pool[i].nlcs;
return ans;
}
void sam_insert(int ch,int len){
state* curr = &pool[total++];
curr->length = curr->nlcs = len;
state* p = last;
while(p && !p->next[ch]) p->next[ch]=curr,p=p->link;
if(!p){
curr->link = head;
}else{
state* q = p->next[ch];
if(p->length +1 == q->length){
curr->link = q;
}else{
state* clone = &pool[total++];
*clone = *q;
clone->length = clone->nlcs = p->length +1;
while(p && p->next[ch]==q) p->next[ch]=clone,p=p->link;
curr->link = q->link = clone;
}
}
last = curr;
}
void sam_traverse(state** p,int& len,int ch){
while(*p!=head && (*p)->next[ch]==NULL){
*p = (*p)->link;
len = (*p)->length;
}
if((*p)->next[ch]){
*p = (*p)->next[ch];
len++;
}
if(len > (*p)->lcs) (*p)->lcs = len;
}
char A[MAX];
int lenA=0;
int lcs(){
sam_init();
scanf("%s",A);
lenA = strlen(A);
FOR(i,0,lenA-1) sam_insert(A[i]-'a',i+1);
sam_track(strlen(A));
while(scanf("%s",A)!=EOF){
lenA = strlen(A);
int l = 0;
state* p = head;
FOR(i,0,lenA-1){
sam_traverse(&p,l,A[i]-'a');
}
sam_updateBests();
}
return sam_best();
}
int main(){
printf("%d\n",lcs());
return 0;
}
Saturday, June 20, 2015
SPOJ::LCS2 - Longest Common Substring II
LCS2 problem can be solved by using SuffixAutomata a.k.a DAWG.
I have written a small writeup on DAWGshere.
I suggest you to go through it, if you are not comfortable with DAWGs.
Tuesday, August 27, 2013
[Algorithms] Suffix Automata (DAWG)
KeyWords: string-matching, pattern-matching, indexing, inverted text, finite-automata, suffix-trees, suffix-automata,suffix-tries, factor-automata, music identification, Directed Acycle Word Graph (DAWG).
Let me name some common problems on string.
finding Least Common String of strings, Sub String search, Palindromes, Angarams,
Dictionary search, Commonly occuring string (Atom String), unique significant substring/pattern,
least common prefix, least common suffix, whats not in the list.
The key point for solving all of these problems is , maintain all data about a string.
All data about a string means {All prefix substrings,All suffix substrings, All sub-strings} .
What matters here ??
You can solve string related problems using, either Brute Force method or using some Data Structure which will allow you to store data about string, considering your time/space complexities.
the way your data-structure stores data about the string? -Time and space taken for processing of the string.
the way your data-structure retrieves data about the string?- Query response time /time taken to retrieve the data.
If you are going to use data-structures, here are the few structure that you'll obvisouly look out for.
Data about strings can be comprised in either a Suffix-Tree/Trie or Suffx-Array or Finite-Automata or Factor-Oracle.
So many people did a vast research on the area of string processing.If this area interests you as well, then you should go throught the sources mentione at the end of this post.
Since, space-time are driving factors in dealing with large data, i prefer to construct a suffx automata(DAWG), for the problems on strings.
Examples of DAWGs:
For String ""
For String "a"
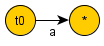
For String "aa"

For String "ab"
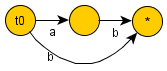
For String "aba"
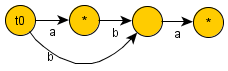
For String "abb"
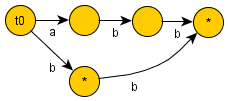
For String "abbb"
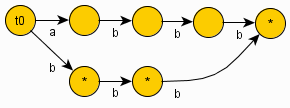
Explanation(Example String: "GCAGAGAG"):
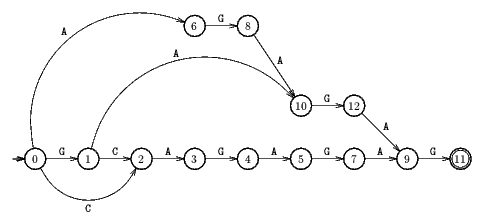
State-3 is cloned as State-6 while inserting 2nd 'A', after state-4, to allow DAG Flow for the suffix string AGAGAG,AGXXXX
State-4 is cloned as State-8 while inserting 2nd 'G', after state-6, to allow DAG Flow for the suffix string GAGAG,GAXXX.
...Just do some work around on this string further, you will understand.
Constructing Suffix-Automata in O(N)-Time / O(N logK) space(Forward DAWG Matching algorithm):
Forward DAWG Matching algorithm, which is smallest suffix automation with Deterministic Finite Automaton.How to Construct: 1. Define the statetypedef struct state{ int length; //Length of the DAWG till this state state* prev; //Link to previous transition state in the DAWG state* next[ALPHA_MAX]; //Links to next transition state in the DAWG } state;2. Automata is constructed with set of states and transition from state-to-state. So define your Automata which comprises of the states, variables to track states and methods that enables to do state transitions.typedef struct SAM{ /*FSM Variables*/ state pool[MAX]; //You need a pool of states, from where you can pick a raw state to include in the DAWG. int count; //You need to track number of states present in the DAWG. state* head,last; //You need to track your head of the DAWG and last State of the DAWG. /*FSM Methods*/ void SAM_init(); //Initialize your Finite state Machine. voidSAM_extend(int input); //Based on the input extend states in your FSM(Finite State Machine) } SAM;3. Initialization of FSM.void SAM::SAM_init(){ memset(pool,0,sizeof(pool)); count=0; head=last=&pool[count++]; }4. Extending the FSM.void SAM::SAM_extend(int input){ state* new_state = &pool[count++]; new_state->length = 1 + last->length; state* p = last; for( ; p && !p->next[input]; p->next[input]=new_state,p=p->prev); if(!p){ new_state->prev = head; }else{ state* q = p->next[input]; if(p->length +1 == q->length){ new_state->prev = q; }else{ state* clone = &pool[total++]; *clone = *q; clone->length = p->length +1; for(;p && p->next[input]==q;p->next[input]=clone,p=p->prev); new_state->prev = q->prev = clone; } } last = new_state; }5. You can include other methods, If required (like below method, which i used it for the traversal of the DAWG.)void SAM::SAM_traverse(state** p,int& len,int input){ while(*p!=head && !(*p)->next[input]){ *p = (*p)->link; len = (*p)->length; } if((*p)->next[input]){ *p = (*p)->next[input]; len++; } }Sources: http://www.cs.nyu.edu/~mohri/pub/nfac.pdf http://cbse.soe.ucsc.edu/sites/default/files/smallest_automaton1985.pdf http://www-igm.univ-mlv.fr/~lecroq/string/fdm.html#SECTION00220 http://e-maxx.ru/algo/suffix_automata http://www-igm.univ-mlv.fr/~lecroq/string/node1.html Practise problems: http://www.spoj.com/problems/LCS/ http://www.spoj.com/problems/LCS2/
Thursday, August 1, 2013
SPOJ-2916::Can you answer these queries V
http://www.spoj.com/problems/GSS5/ Typical problem statement can be seen as below. Problem: Given a array of numbers a[1...n] , and a Query(x1,y1,x2,y2). Query(x1,y1,x2,y2) = Max { A[i]+A[i+1]+...+A[j] ; x1 <= i <= y1 , x2 j <= y2 and x1 <= x2 , y1 <= y2 }. Lets analyze this query... Wait a minute...!! Have you read my post on GSS1 problem ?? Have you ever Solved GSS1 problem ?? If your answer is NO, then I suggest you to do that problem first. http://code.karumanchi.me/2013/07/spoj-1043can-you-answer-these-queries-i.html Here two cases araises based on {x1 <= i <= y1 , x2 j <= y2 and x1 <= x2 , y1 <= y2 }. Case-1: (x1,y1) and (x2,y2) doesn't overlap. Case-2: (x1,y1) and (x2,y2) overlaps. Case-1::No Overlapping result would be (x1,y1).bestRightSum + (y1+1,x2-1).Sum +(x2,y2).bestLeftSum;Case-2::No Overlapping result would be max of { (x1,x2-1).bestRightSum + (x2,y2).bestLeftSum, (x1,y1).bestRightSum + (y1+1,y2).bestLeftSum, (x2,y1).bestSum }

Implementation of the Same - Solution
// =====================================================================================
// Filename: GSS5.cpp
// Description:
// Author: BrOkEN@!
// =====================================================================================
#include<cassert>
#include<cctype>
#include<climits>
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<ctime>
#include<bitset>
#include<deque>
#include<list>
#include<map>
#include<queue>
#include<set>
#include<stack>
#include<vector>
#include<fstream>
#include<iostream>
#include<sstream>
#include<streambuf>
#include<algorithm>
#include<iterator>
#include<new>
#include<string>
#include<utility>
template< class T >
inline T maxOfThree(T a, T b, T c){
return max(max(a,b),c);
}
#define FOR(i,a,b) for(typeof((a)) i = (a); i <= (b) ; ++i )
#define REV_FOR(i,b,a) for(typeof((b)) i = (b); i >= (a) ; --i )
#define FOREACH(it,x) for(typeof((x).begin()) it=((x).begin()); it != ((x).end()); ++it)
#define REV_FOREACH(it,x) for(typeof((x).rbegin()) it=((x).rbegin()); it != ((x).rend()); ++it)
using namespace std;
typedef pair<int,int> PI;
typedef vector<PI> VI;
typedef struct node{
int bestLeftSum,bestRightSum,Sum,bestSum;
node merge(node& l,node& r){
bestLeftSum = max(l.bestLeftSum,l.Sum+r.bestLeftSum);
bestRightSum = max(l.bestRightSum+r.Sum,r.bestRightSum);
Sum = l.Sum + r.Sum;
bestSum = maxOfThree(l.bestSum,r.bestSum,l.bestRightSum+r.bestLeftSum);
}
node setNode(int val){
bestLeftSum = bestRightSum = Sum = bestSum = val;
}
} node;
const int MAX = 1<<14;
node T[MAX<<1];
int A[MAX];
void init(int Node,int i,int j){
if(i==j){
T[Node].setNode(A[i]);
return;
}else{
int m = (i+j)/2;
init(2*Node,i,m);
init(2*Node+1,m+1,j);
T[Node].merge(T[2*Node],T[2*Node+1]);
}
}
node range_query(int Node,int i,int j,int L,int R){
if(L > R) return T[0];
if(i==L && R==j){
return T[Node];
}else{
int m = (i+j)/2;
if(R<=m){
return range_query(2*Node,i,m,L,R);
}else if(L>m){
return range_query(2*Node+1,m+1,j,L,R);
}else{
node resultNode,left,right;
left = range_query(2*Node,i,m,L,m);
right = range_query(2*Node+1,m+1,j,m+1,R);
resultNode.merge(left,right);
return resultNode;
}
}
}
int query(int N,int x1,int y1,int x2,int y2){
int result =0;
if(y1<x2){
result += range_query(1,0,N-1,x1,y1).bestRightSum;
result += range_query(1,0,N-1,y1+1,x2-1).Sum;
result += range_query(1,0,N-1,x2,y2).bestLeftSum;
}else{
result += maxOfThree(
range_query(1,0,N-1,x1,x2-1).bestRightSum + range_query(1,0,N-1,x2,y2).bestLeftSum,
range_query(1,0,N-1,x1,y1).bestRightSum + range_query(1,0,N-1,y1+1,y2).bestLeftSum,
range_query(1,0,N-1,x2,y1).bestSum
);
}
return result;
}
int main(){
int T=0;
scanf("%d",&T);
int N=0,Q=0,x1=0,y1=0,x2=0,y2=0;
FOR(t,1,T){
scanf("%d",&N);
FOR(i,0,N-1){scanf("%d",&A[i]);}
init(1,0,N-1);
scanf("%d",&Q);
FOR(q,1,Q){
scanf("%d%d%d%d",&x1,&y1,&x2,&y2);
--x1;--y1;--x2;--y2;
printf("%d\n",query(N,x1,y1,x2,y2));
}
}
return 0;
}
SPOJ-1043::Can you answer these queries I
http://www.spoj.com/problems/GSS1/ Typical problem statement can be seen as below. Problem: Given a array of numbers a[1...n] , and a query range [x,y]. query(x,y) should return the sub-sequence sum, whose sum is maximum in the interval [x,y]. Lets analyze this query. Query(x,y) is the maximum of below values where sum(i,j) = a[i]+a[i+1]+......+a[j];
| sum(x,x) | sum(x,x+1) | sum(x,x+2) | .......... | sum(x,y-1) | sum(x,y) |
| sum(x+1,x+1) | sum(x+1,x+2) | .......... | sum(x+1,y-1) | sum(x+1,y) | |
| sum(x+2,x+2) | .......... | sum(x+2,y-1) | sum(x+2,y) | ||
| .......... | .......... | .......... | |||
| sum(y-1,y-1) | sum(y-1,y) | ||||
| sum(y,y) |
Blue::The Color of Left Sum. Where the range starts at 'x' but ends at any where in [x,y].
| sum(x,x) | sum(x,x+1) | sum(x,x+2) | .......... | sum(x,y-1) | sum(x,y) |
| sum(x+1,x+1) | sum(x+1,x+2) | .......... | sum(x+1,y-1) | sum(x+1,y) | |
| sum(x+2,x+2) | .......... | sum(x+2,y-1) | sum(x+2,y) | ||
| .......... | .......... | .......... | |||
| sum(y-1,y-1) | sum(y-1,y) | ||||
| sum(y,y) |
Red::The Color of Right Sum. Where the range starts at somewhere in [x,y] and ends at 'y'.
| sum(x,x) | sum(x,x+1) | sum(x,x+2) | .......... | sum(x,y-1) | sum(x,y) |
| sum(x+1,x+1) | sum(x+1,x+2) | .......... | sum(x+1,y-1) | sum(x+1,y) | |
| sum(x+2,x+2) | .......... | sum(x+2,y-1) | sum(x+2,y) | ||
| .......... | .......... | .......... | |||
| sum(y-1,y-1) | sum(y-1,y) | ||||
| sum(y,y) |
Grey::The Color of Sum of the Elements. Simply sum of all elements in interval [x,y].
| sum(x,x) | sum(x,x+1) | sum(x,x+2) | .......... | sum(x,y-1) | sum(x,y) |
| sum(x+1,x+1) | sum(x+1,x+2) | .......... | sum(x+1,y-1) | sum(x+1,y) | |
| sum(x+2,x+2) | .......... | sum(x+2,y-1) | sum(x+2,y) | ||
| .......... | .......... | .......... | |||
| sum(y-1,y-1) | sum(y-1,y) | ||||
| sum(y,y) |
Green::The Color of nested Query ;). Well, you can see this as the Query(x+1,y-1).
| sum(x,x) | sum(x,x+1) | sum(x,x+2) | .......... | sum(x,y-1) | sum(x,y) |
| sum(x+1,x+1) | sum(x+1,x+2) | .......... | sum(x+1,y-1) | sum(x+1,y) | |
| sum(x+2,x+2) | .......... | sum(x+2,y-1) | sum(x+2,y) | ||
| .......... | .......... | .......... | |||
| sum(y-1,y-1) | sum(y-1,y) | ||||
| sum(y,y) |
Now, you can understand why i had to use these colors.
Lets maintain 4 values. bestLeftSum - Best of all the Left Sums bestRightSum - Best of all the Right Sums Sum - Sum of all the elements bestSum - well we need this to store resultSum of each query (Nested Query ;)) Logically, Query(x,y).resultSum = max (bestLeftSum,bestRightSum,sum,Query(x+1,y-1).bestSum); But still the nested query stuff isn't so good O(N^2) :'(. Why can't we use a tree(SegmentTree) ?? Why not a O(logN) for query?? Lets call the above info {bestLeftSum,bestRightSum,Sum,bestSum} as QueryNode. and given information about QueryNode(L,M) and QueryNode(M+1,R). Can't you be able to determine the QueryNode(L,R) with above information?? QueryNode(L,M) -> l QueryNode(M+1,R) -> r Then For QueryNode(L,R), bestLeftSum = max (l.bestLeftSum,l.Sum+r.bestLeftSum); bestRightSum = max (l.bestRightSum+r.Sum,r.bestRightSum); Sum = l.Sum+r.Sum; bestSum = max(l.bestSum,r.bestSum,l.bestRightSum+r.bestLeftSum); How?? - Check below graphical representation
Implementation of the Same - Solution
// =====================================================================================
// Filename: GSS1.cpp
// Description:
// Created: 05/23/2013 06:41:42 PM
// Author: BrOkEN@!
// =====================================================================================
#include<fstream>
#include<iostream>
#include<sstream>
#include<bitset>
#include<deque>
#include<list>
#include<map>
#include<queue>
#include<set>
#include<stack>
#include<vector>
#include<algorithm>
#include<iterator>
#include<string>
#include<cassert>
#include<cctype>
#include<climits>
#include<cmath>
#include<cstddef>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<ctime>
#define FOR(i,a,b) for(typeof((a)) i=(a); i <= (b) ; ++i)
#define FOREACH(it,x) for(typeof((x).begin()) it=(x).begin(); it != (x).end() ; ++it)
using namespace std;
typedef pair<int,int> PI;
typedef vector<PI> VI;
inline int max2(int a, int b) {return ((a > b)? a : b);}
inline int max3(int a, int b, int c) {return max2(a, max2(b, c));}
const int MAX = 1 << 16;
int a[MAX];
struct node
{
int Sum,bestLeftSum,bestRightSum,bestSum;
node split(node& l, node& r){
} // No Need of Split Function
node merge(node& l, node& r)
{
Sum = l.Sum + r.Sum;
bestLeftSum = max( l.Sum + r.bestLeftSum , l.bestLeftSum );
bestRightSum = max( r.Sum + l.bestRightSum , r.bestRightSum );
bestSum = max( max( l.bestSum , r.bestSum) , l.bestRightSum + r.bestLeftSum );
}
node setValue(int val){
Sum = bestLeftSum = bestRightSum = bestSum = val;
}
};
node T[MAX << 1];
void init(int Node, int i, int j) {
if(i==j) { // Initialize Leaf Nodes
T[Node].setValue(a[i]);
return;
}else{ // Summerize Descendant Nodes Nodes
int m = (i+j)/2;
init(2*Node, i, m);
init(2*Node+1, m+1, j);
T[Node].merge(T[2*Node],T[2*Node+1]);
}
}
void update(int Node, int i, int j,int idx, int val) {
// Update element with index 'idx' in the range [i,j]
if(i==j && i == idx) { // Update the LeafNode idx
T[Node].setValue(val);
return;
}else{ // Summerize Descendant Nodes Nodes
int m = (i+j)/2;
if(idx <=m)
update(2*Node, i, m, idx, val);
else
update(2*Node+1, m+1, j, idx, val);
T[Node].merge(T[2*Node],T[2*Node+1]);
}
}
void range_query(node& resultNode,int Node,int i, int j, int L, int R){ // Search for Node having interval info [L,R] in [i,j]; (i<=L<R<=j)
if(i==L && j==R){
resultNode = T[Node];
return;
}else{
int m = (i+j)/2;
if(R<=m)
range_query(resultNode, 2*Node, i, m, L, R);
else if(L>m)
range_query(resultNode, 2*Node+1, m+1, j, L, R);
else{
node left, right;
range_query(left, 2*Node, i, m, L, m);
range_query(right, 2*Node+1, m+1, j, m+1, R);
resultNode.merge(left,right);
}
}
}
int solve(){
return 0;
}
int main(){
int N=0,M=0;
node res;
scanf("%d",&N);
FOR(i,0,N-1){
scanf("%d", &a[i]);
}
init(1, 0, N-1);
scanf("%d",&M);
int x,y;
FOR(i,0,M-1){
scanf("%d%d",&x,&y);
range_query(res, 1, 0, N-1, --x, --y);
printf("%d\n", res.bestSum);
}
return 0;
}
Monday, July 29, 2013
SPOJ-1557::Can you answer these queries II
This is one of the difficult problems that i have solved. So i've decided to write an article about how to solve this problem.
Logically the problem statement is exactly like below.
Problem: Given a array of numbers a[1...n] (where duplicates are allowed), and a query range [x,y].
query(x,y) should return the sub-sequence sum, whose sum is maximum in the range [x,y] by satisfying uniqueness criteria.
Assume that a[x...y] is a sub-sequence having unique elements(i.e. with out duplicates).
Lets analyze the query asked for this range.
Query for range {x...y} can be expressed as below, assuming that all the queries {query(i,j) where j<y} were answered already.
Lets go little further, do some sample calculations based on n values.
So you might have already observed the pattern that we are looking for.
Now Formal definitions of query(x,y) and b(i,j).
You might have figured out that, after inserting a elment a[j] we are no longer looking at queries query(x,y) where y<j.
Hence we are updating the childrens with the current values as they are being updated.
so Operations required will be,
Following is my code,for which i have got AC after 20 attempts :P.
Be sure to look out for 'long long' ;)
Logically the problem statement is exactly like below.
Problem: Given a array of numbers a[1...n] (where duplicates are allowed), and a query range [x,y].
query(x,y) should return the sub-sequence sum, whose sum is maximum in the range [x,y] by satisfying uniqueness criteria.
Assume that a[x...y] is a sub-sequence having unique elements(i.e. with out duplicates).
Lets analyze the query asked for this range.
Query for range {x...y} can be expressed as below, assuming that all the queries {query(i,j) where j<y} were answered already.
query(x,y) = max {
b(x,y),
b(x+1,y),
b(x+2,y),
.
..
...
b(y,y)
}
where b(i,j) is defined as below.b(i,j) = max {
a[i],
a[i]+a[i+1],
a[i]+a[i+1]+a[i+2],
......
a[i]+a[i+1]+a[i+2]+......+a[j]
}
Lets go little further, do some sample calculations based on n values.
| n-value | possible Queries | b-elements |
|---|---|---|
| 1 | query(1,1) | b(1,1) |
| 2 |
query(1,1),query(1,2)
query(2,2)
|
b(1,1),b(1,2)
b(2,2)
|
| 3 |
query(1,1),query(1,2),query(1,3)
query(2,2),query(2,3)
query(3,3)
|
b(1,1),b(1,2),b(1,3)
b(2,2),b(2,3)
b(3,3)
|
So you might have already observed the pattern that we are looking for.
Now Formal definitions of query(x,y) and b(i,j).
query(x,y) -> is the sub-sequence sum, whose sum is maximum in all sub-sequences by satisfying uniqueness criteria. b(i,j) -> is the maximum sub-sequence in the range[i...j] by satisfying uniqueness criteria.
Algorithm:
Create an array/segment Tree as 'b'. (Segment tree is suggested, will explain that later)
For i = 1 to N
->update the 'b' by inserting the element a[i].
->Answer all the queries query(x,y) where x<=y and y=i.
How to handle repeativeness of the elements ?? Assume that a[j] is the element to be inserted,
a[j] will make its contribution towards the elements b(i,j) {where i<=j}.
Insertion operation is done based on the assumption that,
all the elements in the range a[i...j] will be unique.
Lets assume that there is an element a[m] {where i <= m <= j} which is duplicate of a[j].
By our theory, a[m] might have already made contribution towards the elements b(i,m) {where i<=m}.
so elements b(k,j) {where m+1 <= k <= j} can include a[j] which is unique for them now.
In Other words, a[j] can make contribution to the elmements b(k,j)
{where m+1 <= k <= j and m-is the last know position of a[j].}
i.e
a[j] can be updated in the range b(last[a[i]]+1,j) which preserves our uniqueness condition.
Complexity of the Query. ?? To calculate each b(i,j), logN operations are required.(Worst case).
To find max of b(i,j), for a query it will take y-x+1 no.of calulations under that element.
** b(i,j) is calculated based on below, so total j-i+1 child element calculations.
{b(i+0,i+0), b(i+0,i+1), b(i+0,i+2).........b(i+0,j)
b(i+1,i+1), b(i+1,i+2).........b(i+1,j)
b(i+1,i+2).........b(i+1,j)
...........
b(j,j)}
Total Complexity = O(N) = (j-i+1)O(logN) = O((j-i+1)*logN);
worst case O(NlogN).
*** Save the processing time by updating child elements by maintaining a segment Tree.
So the complexity will come down to O(logN)
How to maintain the Segment Tree Node.??/*
Suppose a[j] is to be updated.
Please be aware that all the queries with y<j are already Calculated before hand.
So update the tree only to maintain the queries where y==j.
i.e. At a certain point of time, after updating a[j],
Leaf Nodes: will contain info about the range queries required query(1,j),query(2,j),query(3,j).....query(j,j).
Non-Leaf Nodes: will contain info about controling interval mentioned below them.
So maintain 4-values at each node.
*/
struct node{
int max; //-> Indicates maximum sum in the interval.
int evermax; //-> Indicates maximum sum the history of this range.
int change; //-> Indicates the value to be modified in the given range.
int everchange; //-> Indicates the value to be modified in the history of this range.
};
For example take the below input.4 4 -2 3 -2Inserting the A[4] = -2 in the sequence, the tree will look like.
(5,5,0,0)
(5,5,0,0) (3,3,-2,0)
(0,0,5,5) (0,0,1,1) (0,0,3,3) (0,0,0,0)
Look at the Leaf nodes, these nodes will address these queries with y==4. May be you can name them as result nodes. :D (5,5,0,0)
(5,5,0,0) (3,3,-2,0)
(0,0,5,5) (0,0,1,1) (0,0,3,3) (0,0,0,0)
q(1,4) q(2,4) q(3,4) q(4,4)
Look at the Non-Leaf nodes, they will have the control information(change,everchange), may be you can name them as control nodes. ;) (5,5,0,0) -> control the interval (1,4)
(5,5,0,0) (3,3,-2,0)
control the interval (1,2) control the interval (3,4) -> -2 will be included in (3,4) range only
(0,0,5,5) (0,0,1,1) (0,0,3,3) (0,0,0,0)
Operations required:You might have figured out that, after inserting a elment a[j] we are no longer looking at queries query(x,y) where y<j.
Hence we are updating the childrens with the current values as they are being updated.
so Operations required will be,
updateChilds(node& left,node& right)//with the current insertion values(i.e changes required are propagated.)
clearNode() // Clear the non-Leaf nodes.
updateNode(node& left,node& right) // Make control nodes are also capable of mataining the result information.
setNode(int val) //Set result nodes to the respective values.
Following is my code,for which i have got AC after 20 attempts :P.
Be sure to look out for 'long long' ;)
// =====================================================================================
// Filename: _GSS2.cpp
// Description:
// Created: 07/25/2013 08:42:25 PM
// Author: BrOkEN@!
// =====================================================================================
#include<fstream>
#include<iostream>
#include<sstream>
#include<bitset>
#include<deque>
#include<list>
#include<map>
#include<queue>
#include<set>
#include<stack>
#include<vector>
#include<algorithm>
#include<iterator>
#include<string>
#include<cassert>
#include<cctype>
#include<climits>
#include<cmath>
#include<cstddef>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<ctime>
#define TIMER 0
#define FOR(i,a,b) for(typeof((a)) i=(a); i <= (b) ; ++i)
#define FOREACH(it,x) for(typeof((x).begin()) it=(x).begin(); it != (x).end() ; ++it)
template< class T > inline T _max(const T a, const T b) { return (!(a < b) ? a : b); }
using namespace std;
const int MAX = 100001;
const int INF = 0x7f7f7f7f;
//const int INF = 0;
typedef pair<int,int> PI;
typedef vector<PI> VI;
typedef long long int __int;
typedef struct node
{
__int max,evermax,change,everchange;
node split(node& l, node& r){
} // No Need of Split Function
node updateChilds(node& l, node& r){
l.everchange = _max(l.everchange,l.change+everchange);
l.change += change;
r.everchange = _max(r.everchange,r.change+everchange);
r.change += change;
}
node setNode(int val){
change += val;
everchange = _max(change,everchange);
}
node clearNode(){
change = 0;
everchange = -INF;
}
node updateNode(node& l, node& r){
max = _max(_max(l.max,l.evermax+l.everchange),_max(r.max,r.evermax+r.everchange));
evermax = _max(l.evermax+l.change,r.evermax+r.change);
}
} node;
typedef struct query{
int l,r,p;
} query;
int a[MAX],lastp[MAX<<1],lastq[MAX];
__int ans[MAX];
node T[1<<18];
query q[MAX];
void update(int node, int i, int j, int a, int b, int val) {
if(a <= i && j <= b) {
T[node].setNode(val);
}
else {
int m = (i + j)/2;
T[node].updateChilds(T[2*node],T[2*node+1]);
T[node].clearNode();
if(a <= m) update(2*node, i, m, a, b, val);
if(m < b) update(2*node+1, m+1, j, a, b, val);
T[node].updateNode(T[2*node],T[2*node+1]);
}
}
__int range_query(int node, int i, int j, int a, int b) {
if(a <= i && j <= b){
return _max(T[node].max,T[node].evermax + T[node].everchange);
}
else {
int m = (i + j)/2;
T[node].updateChilds(T[2*node],T[2*node+1]);
T[node].clearNode();
T[node].updateNode(T[2*node],T[2*node+1]);
return _max((a <= m ? range_query(2*node, i, m, a, b) : -INF),
(m < b ? range_query(2*node+1, m+1, j, a, b) : -INF));
}
}
int main(){
int N=0;
scanf("%d",&N);
FOR(i,1,N){
scanf("%d", &a[i]);
}
int M=0;
scanf("%d",&M);
FOR(i,1,M){
scanf("%d%d",&q[i].l,&q[i].r);
q[i].p = lastq[q[i].r];
lastq[q[i].r]=i;
}
FOR(i,1,N){
update(1, 1, N, lastp[a[i]+100000] + 1, i, a[i]);
lastp[a[i]+100000] = i;
for(int j=lastq[i];j;j=q[j].p){
ans[j]=range_query(1, 1, N, q[j].l, q[j].r);
}
}
FOR(i,1,M){printf("%lld\n", ans[i]);}
return 0;
}
Tuesday, May 28, 2013
[Algorithms] Binary Indexed Trees
Sources:
http://community.topcoder.com/tc?module=Static&d1=tutorials&d2=binaryIndexedTrees
http://demonstrations.wolfram.com/BinaryIndexedTree/
http://www.algorithmist.com/index.php/Fenwick_tree
Basic Idea:
Given a set of 'n' Elements(Set F), then summarize set-F with a resulting data structure Tree(set T), with the equal number of elements as F.
For Each index in T , T[index] summarizes the information about the elements from 'index-2^r+1' to 'index' in F.
In other words, T[index] is responsible for elements F[index-2^r+1] .....F[index], where 'r' is the position of the last occurance of '1'.
Eg: See the below calculation to find out the range of each index[Max Value of index is 15 here].
Note: Neither set F is defined here nor T is derived here. This calculation is given to explain how ranges are considered at each Index of the Tree.
 |
Table of Responsibility
|
| Table of Responsibilty (Each index'ed element represents range [m,n] |
|
 | |
| Pictorial representation |
Define the Tree:
Now, since we know responsibility of ranges, set 'Tree' can be derived from a defined set 'F'.

 | |
| Pictorial Representation |
How to Implement:
To implement the above idea, we need to follow the below procedures.
1. Find 'r' - i.e the last occurance of '1'.
2. Calulate the range[m,n] for each index based on r of that 'index'.
3. Represent set F as Cumulative frequencies.
4. Build the Tree based on the ranges given. T[index] = C[n]-C[m-1]; where [m,n] is the range covered by index.
5. Supporting required Operations on the implemeted Tree.
a.Read the cumulative frequency.
b.Read the actual frequency.
c.Update the frequency and Update the tree
d.Given a cumulative frequency, find the index. [This is not required As of now]
e.UpScale/Downscale the entire frequencies in the Tree and update tree accordingly. etc.
Finding the Last Digit:
Okay, you are given a number 'N' and we need to find the position of last digit '1'.
representing N in binary format binary(N) = a1b [where 'b' is sequence of 0's and 'a' is sequence of 1's&0's , B is Sequence of all 1's]
representing N'( N's Complement) in binary format binary(N') = (a1b)' +1 = a'1'b'+1 = a'0B +1 = a'1b
N&N' = a1b & a'1b = (0..0)1(0..0) -> Last occurance of '1' is isolated.
Steps - 2,3,4 are easy to implement. At the end of step-4 , building of the BIT would be completed.
BIT should support necessary operations which are useful in range queries, otherwise its useless.
Reading the Cumulative Frequency:
For example, we want to read cumulative frequncy at index=13.
C[13]=C[1101] = Tree[1101] + Tree[1100] + Tree[1000] + T[0000] = 3 + 11 + 12 + 0 = 26;
(i.e. Toggle the 1's from Right to left till the last; T[0000]=0 always coz we never use T[0], we leave that as it is in BITs;)
//psuedoCode:
int readCumulative(int idx){
int sum=0;
while(idx>0){
sum += Tree[idx];
idx -= (idx & -idx);
}
return sum;
}
Reading the Actual Frequency:
Simple approach: Actual frequency can be expressed as below.
F[idx] = C[idx]-C[idx-1];
//psuedoCode:
int readActual(int idx){
return readCumulative(idx) - readCumulative(idx-1);
}
But the complexity will be more(2*O(log maxVal)). So think of an optimal way.
C[13] = C[1101] = Tree[1101] + Tree[1100] + Tree[1000] + T[0000];
C[12] = C[1100] = Tree[1100] + Tree[1000] + T[0000];
Their Trees are matched after 12. So start with sum at idx=13 and substract the nodes till they match.
//psuedoCode:
int readActual(int idx){
int sum = Tree[idx];
if(idx>0){
int z = idx - (idx & -idx);
idx--;
while(idx!=z){
sum -= Tree[idx];
idx -=(idx & -idx);
}
}
}
Update the frequency and Update the tree:
If index 'idx''s frequency is updated , then all the Tree indexes which holds responsibility for this index are have to be updated.[Where ever the r of this idx is toggled.]
//psuedoCode:
void update(int idx,int val){
while(idx <=maxVal){
Tree[idx] += val;
idx += (idx & -idx);
}
}
UpScale/Downscale the entire Tree:upscale/downscale by factor c.
//psuedoCode:
void scale(int c){
for(int i=1;i<=maxVal;i++){
update(i, -(c-1)*readActual(i)/c);
}
}
//or Simple way is
void scale(int c){
for(int i=1;i<=maxVal;i++){
Tree[i] = Tree[i]/c;
}
}
[Algorithms] Segment Trees
Sources: TopCoder, LetUsKode, StackOverFlow and Google.
http://community.topcoder.com/tc?module=Static&d1=tutorials&d2=lowestCommonAncestor
http://zobayer.blogspot.in/
Segment Trees mostly used for storing data and to provide easy access in range queries.
Basic Idea:
Each non-Leaf Node summarizes the information stored at descenedent leaves.
In Other words, Node 'i' will have summarized info about child Nodes at Kth Level.
i.e. childs from i*2^k to (i+1)*s^k -1
Majorly two Operations are can be performed on a node in segTrees.
Merge: Summarize info stored at descendant nodes.
Split: Applying certain operations on descendant nodes.
And the following operations are done one the whole segTree.
Initialize: Initialize the segment tree.
Update: Update info of the leaf node and propagate the change till the root.
Query: Query function to be run over a Range or on a specific node(To check balanced state).
Generalized Code Template (In C++): [Node Structure and Operations done on a Node]
//
//Node Structure
struct node{
<type> <variable> ;
node merge(node& l, node& r){
//Apply your merge logic here.
}
node split(node& l, node& r){
//Apply Split logic here if you have any
}
node setValue(){
//Initialize variable in case of Leafnode creation or updation of a LeafNode
}
};
Generalized Code Template (In C++): [Operation that can be performed on segTree]
//
// initialization of Nodes
void init(int Node, int i, int j) {
if(i==j) { // Initialize Leaf Nodes
T[Node].setValue();
return;
}else{ // Summerize Descendant Nodes Nodes
int m = (i+j)/2;
init(2*Node, i, m);
init(2*Node+1, m+1, j);
T[Node].merge(T[2*Node],T[2*Node+1]);
}
}
//
// Update element with index 'idx' in the range [i,j]
void update(int Node, int i, int j,int idx, <values>) {
if(i==j && i == idx) { // Update the LeafNode idx
T[Node].setValue();
return;
}else{ // Summerize Descendant Nodes Nodes
int m = (i+j)/2;
if(idx <=m)
update(2*Node, i, m, idx, <values>);
else
update(2*Node+1, m+1, j, idx, <values>);
T[Node].merge(T[2*Node],T[2*Node+1]);
}
}
//
// Search for Node having interval info [L,R] in [i,j]; (i <= L < R <= r)
void range_query(node& resultNode,int Node,int i, int j, int L, int R){
if(i==L && j==R){
resultNode = T[Node];
return;
}else{
int m = (i+j)/2;
if( R <= m )
range_query(resultNode, 2*Node, i, m, L, R);
else if( L > m )
range_query(resultNode, 2*Node+1, m+1, j, L, R);
else{
node left,right;
range_query(left, 2*Node, i, m, L, m);
range_query(right, 2*Node+1, m+1, j, m+1, R);
resultNode.merge(left,right);
}
}
}
Practice Problems:
http://www.spoj.pl/problems/BRCKTS/
http://www.spoj.com/problems/GSS3/
http://www.spoj.pl/problems/GSS1/
Subscribe to:
Posts (Atom)